Traditional Read Ablity Formulas Usually Determin the Difficulties of a Text Base on

How to Evaluate Text Readability with NLP
Reader date is a recurrent trouble among all types of readers: adults/children and teachers/students. They all face up the same result: finding books close to their current readability ability, either for casual reading (piece of cake level) or to improve and learn (hard level) without beingness flooded by besides much difficulty which usually results in a harsh experience for most of us.
At Glose, our goal is to enable readers to access books that are gradually more difficult and recommend books that fit their current reading ability.
In this article, we will show how we developed a machine learning arrangement that considerately evaluates text readability.
Text Complexity: Facets and Usage
Text complexity measurement estimates how difficult it is to understand a document. Information technology tin be defined by ii concepts: legibility and readability.
Legibility ranges from character perception to all the nuances of formatting such as assuming, font way, font size, italic, discussion spacing …
Readability, on the other mitt, focuses on textual content such equally lexical, semantical, syntactical and discourse cohesion assay. It is usually computed in a very gauge manner, using boilerplate sentence length (in characters or words) and boilerplate word length (in characters or syllables) in sentences.
A few other text complexity features practice not depend on the text itself, but rather on the reader's intent (homework, learning, leisure, …) and cognitive focus (which can be influenced by ambient racket, stress level, or whatsoever other type of distraction).
Why is it crucial to exist able to measure text readability ?
In the context of carrying of import information to most readers (drugs leaflets, news, authoritative and legal documents), an evaluation of readability helps text writers to adjust their content to their target audience's level.
Another use case is the field of automatic text simplification, where a robust readability metric can supersede standard objective functions (such as a mixture of BLEU and Flesch-Kincaid) used to train text simplification systems.
In this commodity, we will focus solely on estimating text readability using annotated datasets and machine learning algorithms. We implemented them using the scikit-learn framework.
Data
The starting point of whatever machine learning task is to collect data. In our case, nosotros excerpt it from 2 sources:
- Our database at Glose contains more than ane meg books which include effectually 800,000 english books.
- A dataset of 330,000 book identifiers, graded on the Lexile text complexity scale ∈ [-200, 2200].
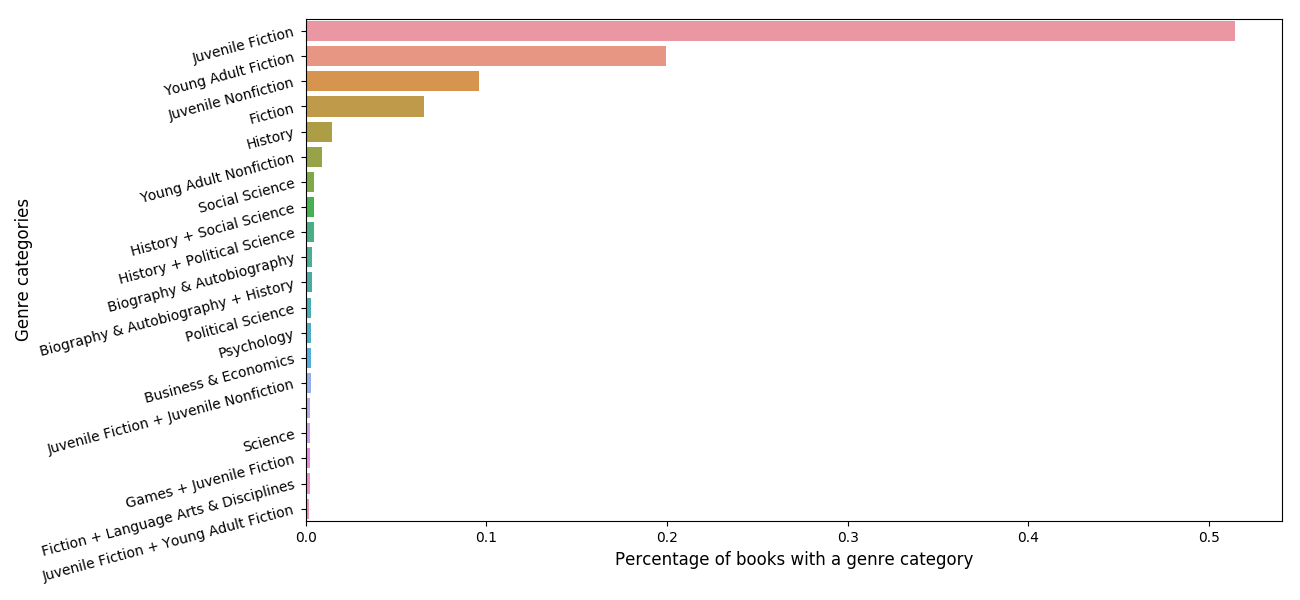
This dataset is biased in two ways:
- The distribution of book genres in our merged dataset is unbalanced (figure in a higher place).
- Information technology assumes that the Lexile score is close to the truthful readability perception of the boilerplate human, which might not be, due to their usage of mainly two features: sentence length and words frequency.

Book identifiers (namely ISBN), are unique to a book'south edition. Each book can have multiple ISBNs due to the big number of editors distributing the same content. In short, each identifier in our dataset maps to multiple identifiers of similar content.
In order to have a unique mapping between ISBN, volume content, and Lexile score, nosotros select an intersection subset (where we have both a book's content in our database and a Lexile annotation) of 17,000 english books.
Book representation
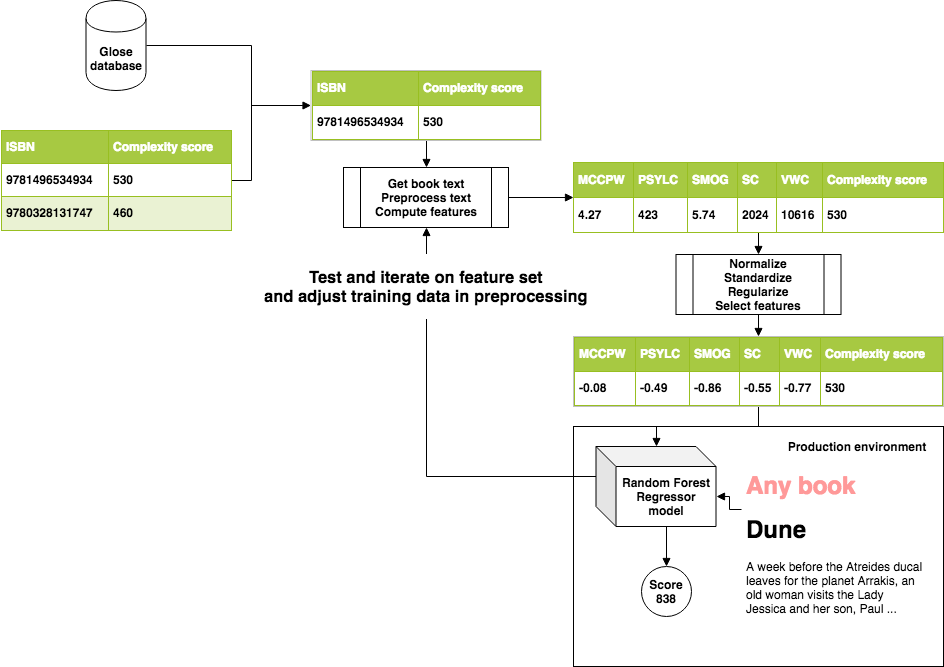
In the beginning stride of our tongue processing pipeline, we clean and tokenize the text into sentences and words. So we have to stand for text as an array of numbers (a.k.a. characteristic vector): here nosotros choose to correspond text by hand-crafted variables in order to embed higher level meaning than a sequence of raw characters.
Each volume is represented by a vector of 50 float numbers, each of them existence a text feature such as:
- Hateful number of syllables per word,
- Mean number of words per sentence,
- Mean number of words considered "difficult" in a sentence (a word is "difficult" if it is not part of an "easy" words reference listing),
- Part-of-Oral communication (POS) tags count per volume,
- Readability formulas such as Flesch-Kincaid and
- Number of polysyllables (more three syllables).
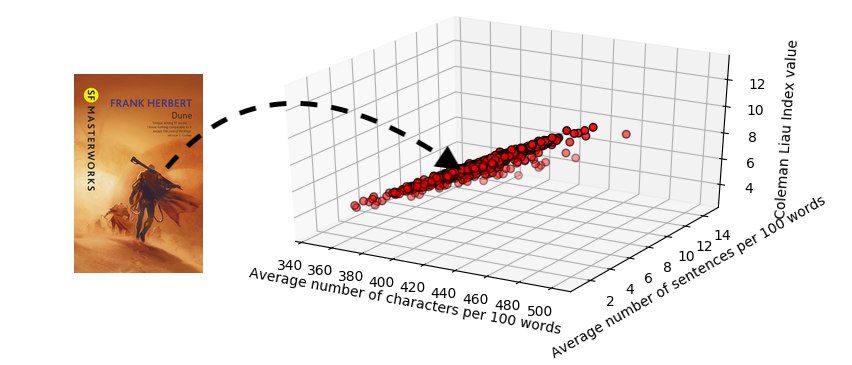
These features are all on dissimilar scales (c.f. figure above), however we would similar to have a similar scale from -1 to i because some of the algorithms we utilize during modelling (Back up Vector Regression with a Linear kernel and Linear regression) assume that the data given as input follows a Gaussian distribution. This procedure, namely standardisation, is about removing the hateful and dividing by the standard deviation of a dataset.
Feature pick
Now that we built a prepare of features representing a text, we would similar to truncate that vector to the most salient features ; the ones that discriminate the most our annotations. Using features that do not comport information related to the target variable (the readability score) is a computation fourth dimension burden to the model, because the inference is washed with more than features than necessary.
To perform this feature selection footstep, we use the LASSO method (scikit-larn implementation) with cross-validation (CV is the process of training and testing models with dissimilar data splits to avert a bias from a specific dataset lodge) considering the difference between execution time with and without 10-fold CV is negligible. Moreover, information technology guarantees to have a model that is less discipline to variance when confronted to existent information.
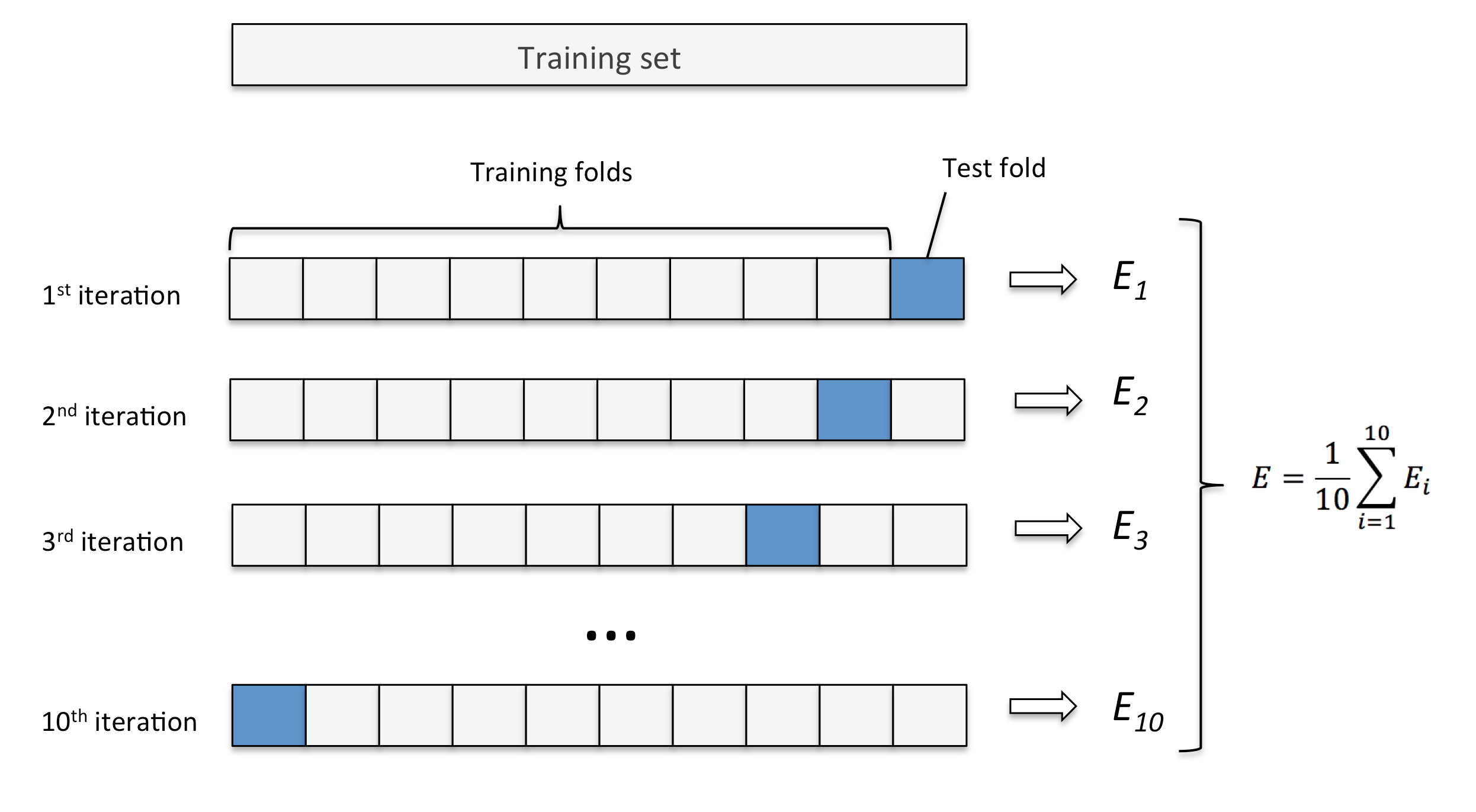
The LASSO method is performed by creating multiple subsets of our feature set. For each feature ready a regression function is fitted using our training information. Then a correlation is computed (using a metric such equally Person, Kendall-Tau or Chi-Square) between each fix's regression function and the readability score. Feature sets are ranked by correlation performance and the best i is selected.
Choosing the right model
Our output variable is numerical and continuous which narrows the spectrum of motorcar learning models applicable to our dataset (regression task). To select an appropriate model, there is several indicators that may guide i's selection, such as the number of features or the number of samples available.
In the case of constrained bayesian algorithms such as Naive Bayes variants (simple or tree augmented), performances are likely to decrease with large number of features. This is due to their inability to build large variable dependencies between an output variable and an explanatory variable. Naive Bayes is built under the assumption that variables are independent, which is less likely the case with longer feature vectors. Tree Augmented Naive Bayes (TAN) allows only one explanatory variable as a dependency of another to predict an output variable. This lack of feature intrication makes these algorithms bad candidates for our characteristic vector length (l), we will not use them in this article.
Notwithstanding, Decision Tree (DT) based algorithms cope very well with high dimensional data (more features) but need lots of data samples (varies every bit a function of algorithm hyperparameters). DTs build rules (for example: average number of words per sentence > 5) and these rules are split up when a given amount of data samples fit them. For example: 10 samples fit the previous rule, we consider that there is too much samples in this rule, and then we build two other rules > 5 AND < 10 and > 10 where we fit respectively four and half dozen samples instead of 10 in one rule. In determination tree algorithms, the number of data samples is a role of model granularity, by treatment overfitting correctly, the more data and features in that location is, the better a DT based model is.
Another arroyo to model selection that we choose to use is Grid Search, this technique is a preparation and testing animate being strength over a set of models and a prepare of hyper parameters for each model.
Pros: Easy to setup, less preliminary analysis of dataset, specific model knowledge isn't much needed, empirical prove (you lot won't know unless yous try).
Cons: Hyper parameter sets definition needs specific model cognition and literature review to reduce computation time, fourth dimension-consuming search (e.one thousand. next figure), no global optimum guarantee.

In our Grid Search, 3 algorithms compete: a Random Woods Regressor (4 hyper parameters), a Linear Regression and a Back up Vector Regressor (2 hyper parameters), the best model is generated through Random Forest regression.
Interpreting readability scores
We now have a product grade model that takes a volume'south feature vector (obtained through pre-processing) equally input and gives a readability score as output. In order to display a comprehensible metric to users (particularly pre-college students), we would similar to have a more than meaningful representation of this score by converting it to grade level bins, we employ the following formula to ascertain those bins.
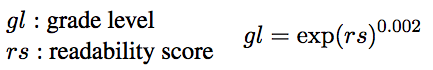
On the following figure we tin can see the almost interesting sections of the readability scale for the students that will read their books on Glose. A teacher can follow a educatee's progression on this scale by monitoring the mean class level of the books he reads.
Performance
Overall our best model achieves around 0.88 for the metric R² which explains 88% of our test set variance. R², as well known as coefficient of determination, is the metric we utilize to test our regression algorithm. The resulting value we get from it ranges from 0 to ane and Random Wood is optimised to converge to one. This value is the explained variance accounted past our model: the higher it is, the less exam information samples we detect outside of our model'southward prediction error range.
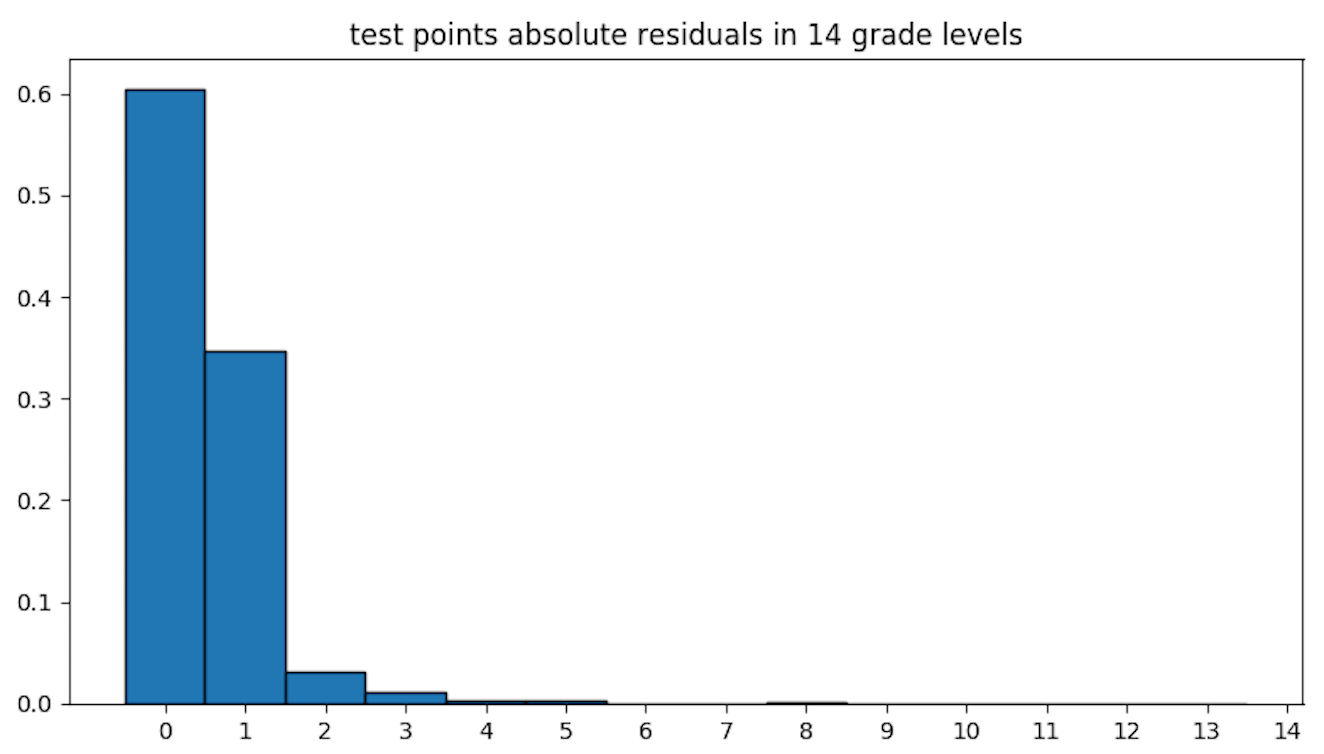
On the figure above we encounter that most of our predictions (60%) fall in the correct course level, whereas virtually 35% in just ane grade level higher up or beneath ground truth. Adjacent precision is equal to 95%, this metric is more relaxed than precision as it allows up to ane grade level error.
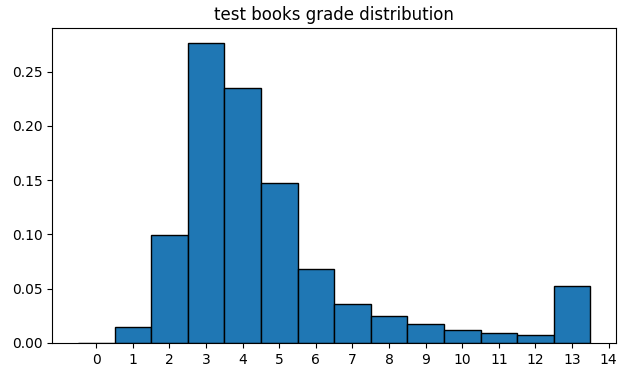
All the same, when nosotros audit the residuals per course level and the distribution of class levels over our test ready, nosotros realise that most of our errors (yellow, orange and cherry-red bars) happen on grade levels with fewer samples (levels vii to 12 included).
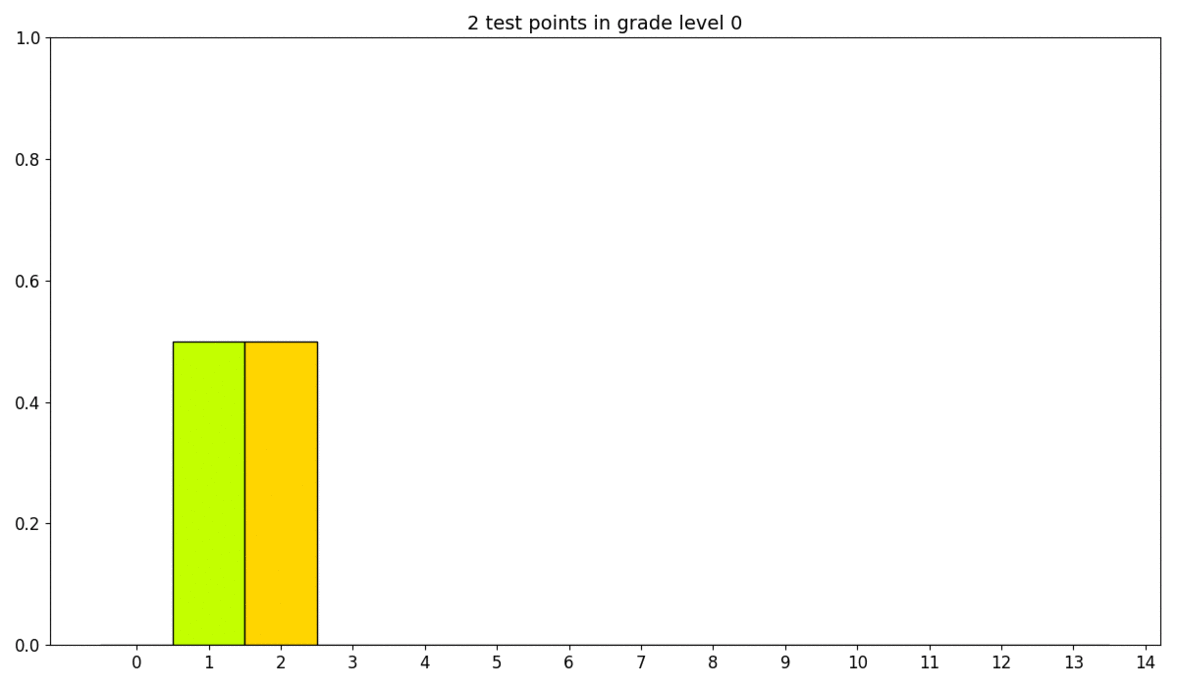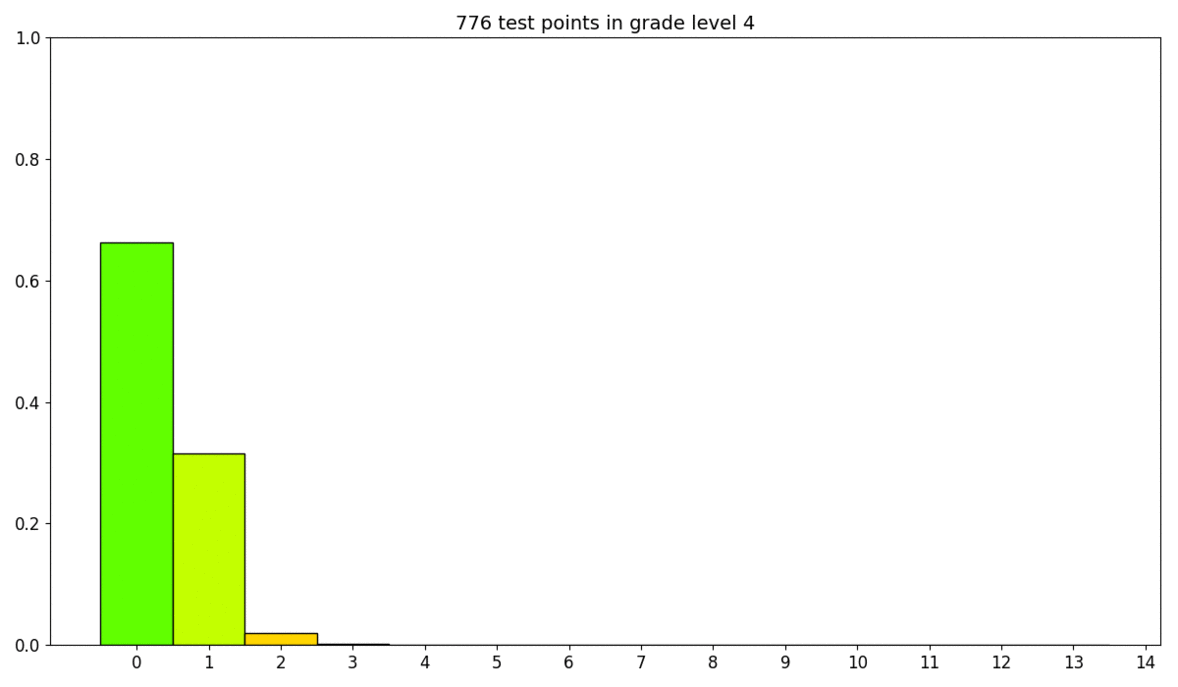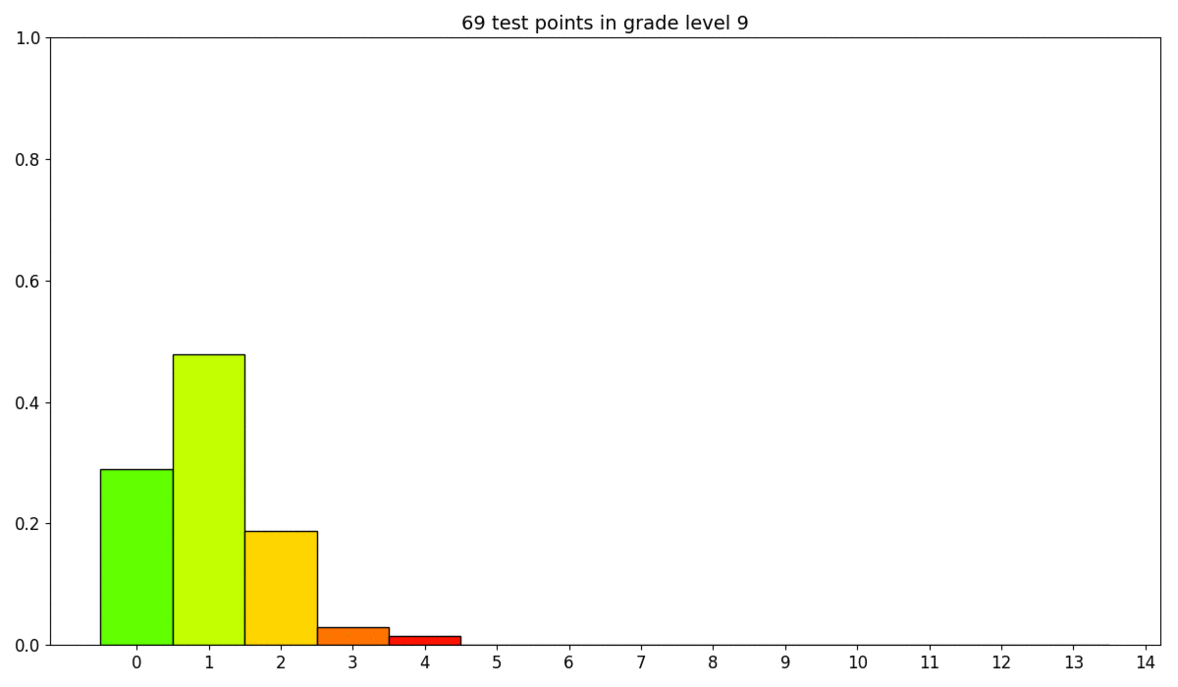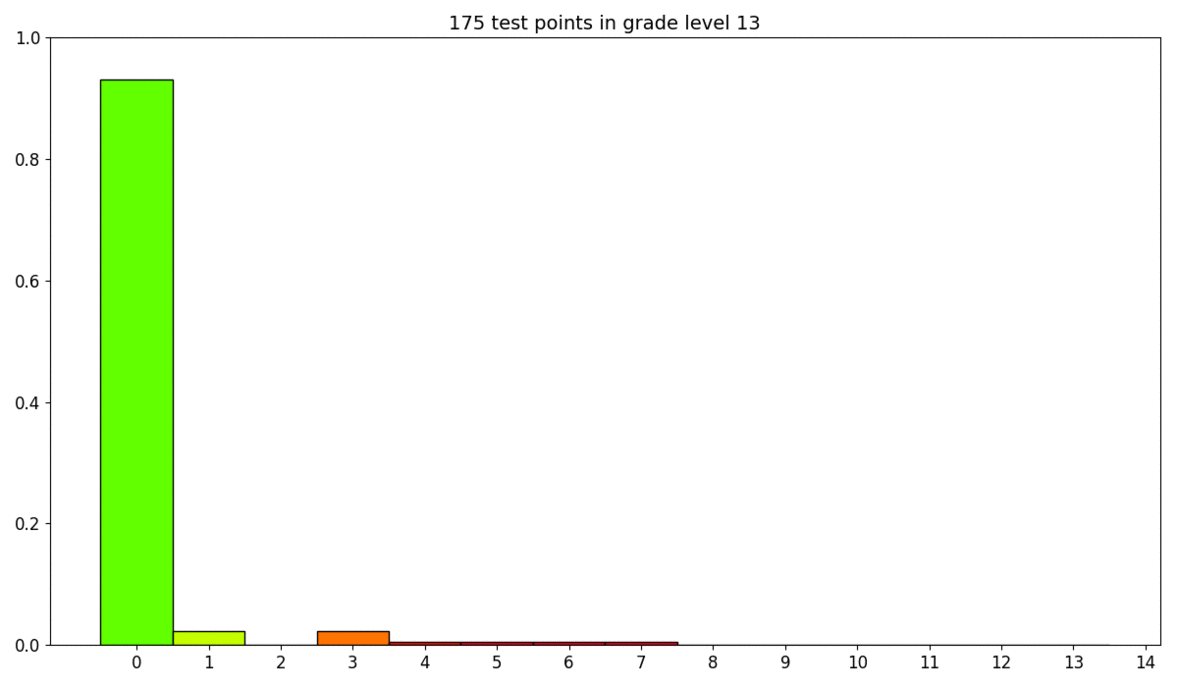
Statistically, our results seem satisfactory. Nonetheless we have room for comeback with this arroyo and we are going to evaluate the robustness of our model with human experts giving their feedback in the loop.
Decision and outlook
Every bit a TL;DR and a takeaway of this post, yous should have learned:
- What is text complexity, and why is it meaningful.
- How a automobile learning pipeline is designed to create a production model.
- A few specifics about parts of this pipeline such every bit features and models selection.
- That this post's readability score is 878 which is lower compared to TIGS: An Inference Algorithm for Text Infilling with Gradient Search that reaches the score 992 on our scale, whereas In Search of Lost Time by Marcel Proust stands at 1441.
As a premise of our next commodity, nosotros are currently working on some other approach to evaluate text readability using neural language models as comprehension systems to infill Cloze tests (text chunks with blank words). The preparation stage of this other approach is unsupervised and has the reward of being linguistic communication agnostic.
greenalacertut1954.blogspot.com
Source: https://medium.com/glose-team/how-to-evaluate-text-readability-with-nlp-9c04bd3f46a2
0 Response to "Traditional Read Ablity Formulas Usually Determin the Difficulties of a Text Base on"
Post a Comment